Hashing dan Binary Tree
Hashing
Pengertian hashing secara praktis adalah pengawalan suatu dokumen apakah sudah berubah atau belum. Pada proses hashing ini bit-bit dari masing karakter dalam dokumen akan dihitung sedemikian rupa dengan algoritma tertentu dan akan menghasilkan suatu hasil tertentu dengan panjang yang telah ditentukan. Secara teknis pengubahan satu huruf saja dalam satu dokumen ini akan mengubah hashnya.
Teknik ini dipakai jika kita mengirimkan dokumen. Kita akan mengirimkan dokumen dan juga hashnya. Penerima akan menghitung ulang nilai dari hashnya, jika hashnya hasil perhitungan sama dengan hash yang dikirimkan sama maka berarti dokumen utuh belum ada yang mengubah. Sebaliknya jika hash yang dihitung berbeda dengan yang yang dikirimkan maka bisa dipastikan dokumen telah ada perubahan.
Fungsi Hashing
1. Untuk dua buah key yang sama, hasil hashing-nya selalu sama.
2. Memiliki kompleksitas rendah.
3. Meminimalkan collision (akan dijelaskan pada bagian selanjutnya).
Pada bagian sebelumnya, saya memberi contoh fungsi hashing sederhana. Sebenarnya fungsi hashing itu bebas, terserah Anda ingin mendefinisikannya seperti apa. Namun, diharapkan fungsi hashing memiliki kriteria sebagai berikut:
Pada kebanyakan kasus, kompleksitas fungsi hash dapat dianggap O(1). Sehingga operasi update dan read bekerja dalam O(1).
Kembali pada contoh fungsi hash yang saya berikan. Apakah Anda menyadari hal yang buruk dari fungsi ini?
Beberapa string sangat mungkin memiliki nilai hash yang sama! Sebagai contoh, "abca", "aabc", dan "baca" sama-sama memiliki nilai hash 7. Akibatnya, hash table akan bingung membedakan mahasiswa bernama "aabc", "abca", dan "baca"!
Collision dapat ditangani. Beberapa cara yang saya ketahui:
Contoh teknik yang digunakan adalah linear/quadratic probing. Saya tidak menjelaskan bagian ini karena menurut saya kurang cocok digunakan saat kompetisi. Kalian yang tertarik bisa mengunjungi artikel ini.
Idenya sederhana. Kita dapat mengganti array pada direct addressing table menjadi "array of linked list". Misalnya "array of linked list" ini bernama T. Setiap elemen pada linked list T[i] menyimpan sejumlah pasangan key dan value untuk memiliki nilai hash key berupa i.
Ketika kita hendak menyimpan suatu nilai ke T[i] dan terjadi collision (sudah ada isinya), kita cukup tambahkan elemen baru pada T[i]. Bentuknya akan menjadi seperti rantai. Berikut ilustrasinya:
Binary Tree
Tree merupakan salah satu bentuk struktur data tidak linear yang menggambarkan hubungan yang bersifat hirarkis (hubungan one to many) antara elemen-elemen. Tree bisa didefinisikan sebagai kumpulan simpul/node dengan satu elemen khusus yang disebut Root dan node lainnya terbagi menjadi himpunan-himpunan yang saling tak berhubungan satu sama lainnya (disebut subtree). Untuk jelasnya, di bawah akan diuraikan istilah-istilah umum dalam tree:
a) Prodecessor : node yang berada diatas node tertentu.
b) Successor : node yang berada di bawah node tertentu.
c) Ancestor : seluruh node yang terletak sebelum node tertentu dan terletak pada jalur yang sama.
d) Descendant : seluruh node yang terletak sesudah node tertentu dan terletak pada jalur yang sama.
e) Parent : predecssor satu level di atas suatu node.
f) Child : successor satu level di bawah suatu node.
g) Sibling : node-node yang memiliki parent yang sama dengan suatu node.
h) Subtree : bagian dari tree yang berupa suatu node beserta descendantnya dan memiliki semua karakteristik dari tree tersebut.
i) Size : banyaknya node dalam suatu tree.
j) Height : banyaknya tingkatan/level dalam suatu tree.
k) Root : satu-satunya node khusus dalam tree yang tak punya predecssor.
l) Leaf : node-node dalam tree yang tak memiliki seccessor.
m) Degree : banyaknya child yang dimiliki suatu node.
Beberapa jenis Tree yang memiliki sifat khusus :
1) Binary Tree
Jenis-jenis Binary Tree :
a) Full Binary Tree
Binary Tree yang tiap nodenya (kecuali leaf) memiliki dua child dan tiap subtree harus mempunyai panjang path yang sama.
b) Complete Binary Tree
 Mirip dengan Full Binary Tree, namun tiap subtree boleh memiliki panjang path yang berbeda. Node kecuali leaf memiliki 0 atau 2 child.
Mirip dengan Full Binary Tree, namun tiap subtree boleh memiliki panjang path yang berbeda. Node kecuali leaf memiliki 0 atau 2 child.
c) Skewed Binary Tree
 Yakni Binary Tree yang semua nodenya (kecuali leaf) hanya memiliki satu child.
Yakni Binary Tree yang semua nodenya (kecuali leaf) hanya memiliki satu child.
Implementasi Binary Tree
Binary Tree dapat diimplemntasikan dalam Pascal dengan menggunakan double Linked List. Untuk nodenya, bisa dideklarasikan sbb :
Type Tree = ^node;
Node = record
Isi : TipeData;
Left,Right : Tree;
end;
Contoh ilustrasi Tree yang disusun dengan double linked list :
(Ket: LC=Left Child; RC=Right Child)
Operasi-operasi pada Binary Tree :
v Create : Membentuk binary tree baru yang masih kosong.
v Clear : Mengosongkan binary tree yang sudah ada.
v Empty : Function untuk memeriksa apakah binary tree masih kosong.
v Insert : Memasukkan sebuah node ke dalam tree. Ada tiga pilihan insert: sebagai root, left child, atau right child. Khusus insert sebagai root, tree harus dalam keadaan kosong.
v Find : Mencari root, parent, left child, atau right child dari suatu node. (Tree tak boleh kosong)
v Update : Mengubah isi dari node yang ditunjuk oleh pointer current. (Tree tidak boleh kosong)
v Retrieve : Mengetahui isi dari node yang ditunjuk pointer current. (Tree tidak boleh kosong)
v DeleteSub : Menghapus sebuah subtree (node beserta seluruh descendantnya) yang ditunjuk current. Tree tak boleh kosong. Setelah itu pointer current akan berpindah ke parent dari node yang dihapus.
v Characteristic : Mengetahui karakteristik dari suatu tree, yakni : size, height, serta average lengthnya. Tree tidak boleh kosong. (Average Length = [jumlahNodeLvl1*1+jmlNodeLvl2*2+…+jmlNodeLvln*n]/Size)
v Traverse : Mengunjungi seluruh node-node pada tree, masing-masing sekali. Hasilnya adalah urutan informasi secara linier yang tersimpan dalam tree. Adatiga cara traverse : Pre Order, In Order, dan Post Order.
Langkah-Langkahnya Traverse :
Ø PreOrder : Cetak isi node yang dikunjungi, kunjungi Left Child, kunjungi Right Child.
Ø InOrder : Kunjungi Left Child, Cetak isi node yang dikunjungi, kunjungi Right Child.
Ø PostOrder : Kunjungi Left Child, Kunjungi Right Child, cetak isi node yang dikunjungi.
Untuk lebih jelasnya perhatikan contoh operasi-operasi pada Binary Tree berikut ini :
2) Binary search Tree
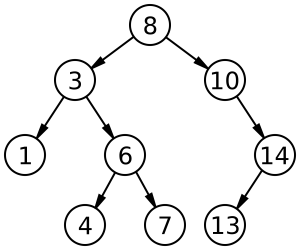
Adalah Binary Tree dengan sifat bahwa semua left child harus lebih kecil daripada right child dan parentnya. Juga semua right child harus lebih besar dari left child serta parentnya. Binary seach tree dibuat untuk mengatasi kelemahan pada binary tree biasa, yaitu kesulitan dalam searching / pencarian node tertentu dalam binary tree. Contoh binary search tree umum :
Pada dasarnya operasi dalam binary search tree sama dengan Binary tree biasa, kecuali pada operasi insert, update, dan delete.
1. Insert : Pada Binary Search Tree, insert dilakukan setelah ditemukan lokasi yang tepat. (Lokasi tidak ditentukan oleh user sendiri).

2. Update : Seperti pada Binary Tree biasa, namun disini uapte akan berpengaruh pada posisi node tersebut selanjutnya. Bila setelah diupdate mengakibatkan tree tersebut bukan Binary Search Tree lagi, maka harus dilakukan perubahan pada tree dengan melakukan perubahan pada tree dengan melakukan rotasi supaya tetap menjadi Binary Search Tree.
3. Delete : Seperti halnya update, delete dalam Binary Search Tree juga turut mempengaruhi struktur dari tree tersebut.

(Keadaan awal merupakan lanjutan gambar sebelumnya)
 Pada operasi di samping, delete dilakukan terhadap Node dengan 2 child. Maka untuk menggantikannya, diambil node paling kiri dari Right SubTree yaitu 13.
Pada operasi di samping, delete dilakukan terhadap Node dengan 2 child. Maka untuk menggantikannya, diambil node paling kiri dari Right SubTree yaitu 13.